什么原因导致缓存读比磁盘读更慢
环境说明
数据库版本: MySQL 8.0.25/MySQL 5.7.21
字符集:utf8mb4
innodb_buffer_pool_size=32G
SSD磁盘
问题描述
表数据为新insert数据,无delete、无update,数据量为1亿,在数据库服务器本地用mysql自带客户端测试全表扫描在磁盘读与缓存读的执行耗时差异(测试期间仅运行select全表扫描,无其他并发sql交叉影响)
mysql 一个数据量为1亿的表,有1个字段,每个字段存1000个字母,idb大小为111G
mysql 一个数据量为1亿的表,有10个字段,每个字段存100个字母,idb大小为111G
mysql 一个数据量为1亿的表,有100个字段,每个字段存10个字母,idb大小为119G
问题1: 在 innodb_buffer_pool_size=32G,关闭 innodb_buffer_pool_dump_at_shutdown = off , 在mysql重启后,全表扫描该表,出现缓存读(非第一次执行)执行耗时 大于 磁盘读(第一次执行)耗时 的原因是什么? ps: 相同表结构与数据,缓存读(非第一次执行)执行耗时 大于 磁盘读(第一次执行)耗时 在机械盘无法复现,在ssd能稳定复现。
问题2: 为什么调整 innodb_old_blocks_pct=95 或者 innodb_old_blocks_time=0 后,缓存读(非第一次执行)执行耗时 **几乎等于** 磁盘读(第一次执行)耗时?
问题3: 关闭 innodb_buffer_pool_dump_at_shutdown = off ,当idb大于 innodb_buffer_pool_size 大小,以全表扫描 第一次执行 与 非第一次执行 使用 innodb buffer pool 有什么区别
mysql 一个数据量为1亿的表,有1个字段,每个字段存1000个字母 建表语句如下:
CREATE TABLE `t_user_1_10000_10000` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`c_name` varchar(10000) NOT NULL DEFAULT '',
PRIMARY KEY (`id`)
) CHARSET=utf8mb4;
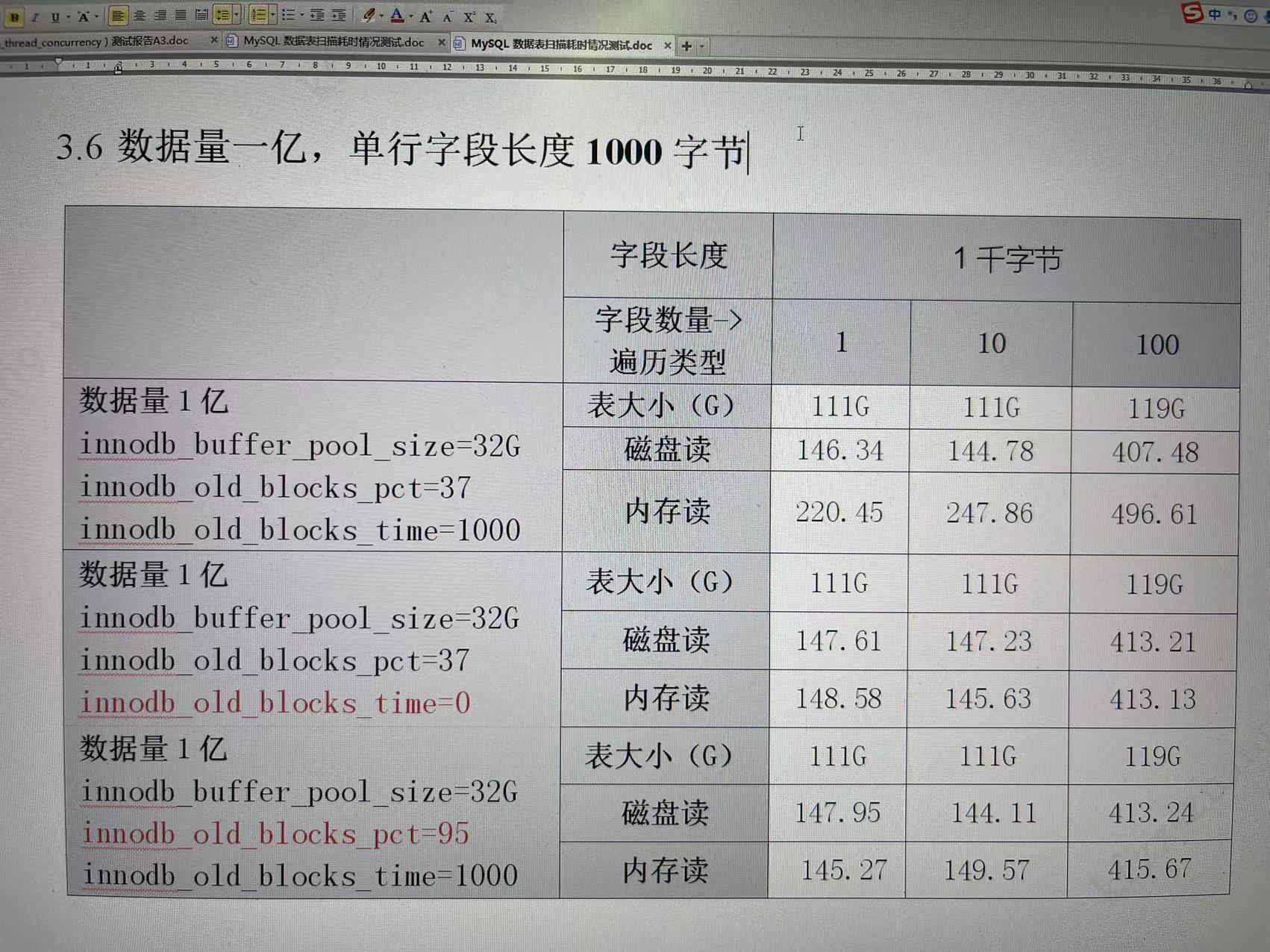
上述图片中 磁盘读与缓存读的执行耗时单位为秒