本文详细介绍KunlunBase 金融级高可靠性技术体系中最关键的部分--- Klustron-storage 存储节点故障恢复机制。KunlunBase用户并不需要理解本文内容就可以有效地使用KunlunBase,本文内容主要是给对KunlunBase核心技术和MySQL事务处理技术感兴趣的读者参考和学习。
社区版MySQL不支持对XA事务的故障恢复,因此无法直接使用作为分布式数据库的存储节点。Kunlun-storage完善和增强了MySQL 的事务恢复机制,其中最主要的是增加了对XA事务的故障恢复机制,为KunlunBase集群故障恢复机制提供了基础条件,这部分技术是KunlunBase核心技术体系的重要组成部分。
经过本文所述的对社区版MySQL事务故障处理的完善和增强,kunlun-storage组成的KunlunBase集群可以正确地处理其集群任何节点的故障,并保证在KunlunBase集群中所有提交成功的事务的ACID属性,从而助力KunlunBase达到金融级高可靠性。
本文先简介KunlunBase集群故障恢复技术,接着介绍分布式数据库集群可能面临的故障以及如果不能有效解决的话可能造成的危害。然后介绍MySQL 事务处理的基础知识和关键技术,以及MySQL故障处理和事务恢复技术。然后重点介绍MySQL在XA事务处理方面的一系列缺陷和漏洞以及KunlunBase如何解决这些问题。
KunlunBase 故障恢复技术概况
KunlunBase 分布式事务两阶段提交流程
为描述方便,先简单介绍两阶段提交算法的技术术语,一个全局事务(global transaction, GT)在若干个存储节点(resource manager, RM)中执行事务分支(transaction branch, LT),由全局事务管理器(GTM)管理其状态和提交过程。在MySQL中,把可以作为分布式事务分支的事务称为XA事务,针对这些事务有专门的SQL语句做事务控制(XA START, XA END, XA PREPARE, XA COMMIT [ONE PHASE])。与这些XA事务相对应的,就是普通事务,也就是通过begin...commit启动和提交的事务,以及autocommit的增删改查(CRUD)语句事务。
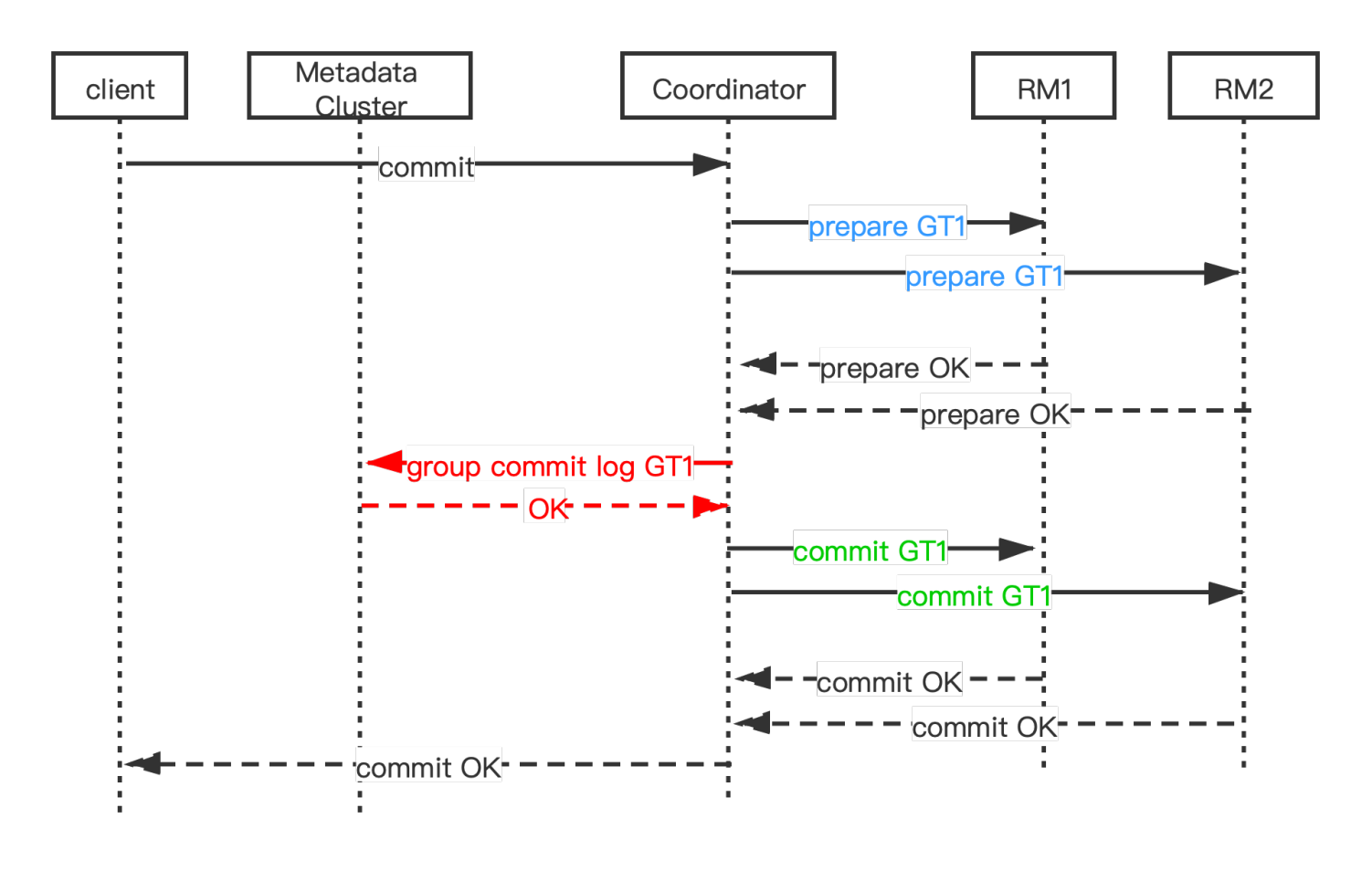
KunlunBase 分布式事务两阶段提交流程示意图
在KunlunBase中执行的事务,如果写入多个shard,那么提交的时候,位于计算节点的全局事务管理器(Global Transaction Manager, GTM)就会发起两阶段提交(Two Phase Commit, 2PC),其流程和方法见这篇文章。
总的来说,之所以两阶段提交,是为了防止多个RM提交事务分支,一部分提交失败的问题。只有第一阶段(PREPARE阶段)完全成功后,才进入第二阶段(COMMIT 阶段)。Prepare阶段如果某些RM失败,那么GTM会让这个全局事务的所有RM回滚其事务分支。如果第一阶段所有RM都成功,那么GTM才开始第二阶段COMMIT,此阶段如果有RM或者计算节点发生故障,那么KunlunBase的cluster_mgr会完成对故障发生时正在提交流程中的所有全局事务做后续跟进处理---全部提交或者全部回滚其事务分支。
数据库集群可能发生的故障及其危害
在任何一个计算机服务器组成的分布式集群中,都可能出现服务器断电或者软硬件故障(硬件设备故障,OS crash,人为误操作,定期维护;系统过载,内外存储空间用尽,系统其他资源用尽),网络故障(网络分区、网络拥塞),甚至机房整体故障(自然灾害,光纤或者电缆被挖断等等)。
对于KunlunBase来说,所有这些故障都可能导致全局事务执行中断或者提交流程中断;如果发生故障的是存储节点,那么也可能导致普通事务或者XA事务分支提交流程中断。这些流程中断如果不能正确地处理,就会导致诸多问题。具体来说,全局事务2PC期间发生故障可能导致:
1、系统逐渐停止服务
如果计算节点或者存储节点故障,可能会残留PREPARED 状态的XA事务。由于这些事务仍然持有事务锁,因此会阻塞与之有锁冲突的其他活跃事务,这些被阻塞的活跃事务也可能已经持有事务锁,因而会导致更多活跃事务被阻塞。最终导致数据库系统逐步无法继续正常运行和提供服务。
2、部分事务分支提交,部分事务分支回滚
这就导致事务的数据更新部分丢失,导致数据不一致和损坏,是严重的错误。
3、如果一个存储节点提交XA事务期间发生故障并且不能正确地恢复这些事务,就可能导致这个存储节点上当时正在提交的事务分支被回滚,这就会导致一个全局事务的一部分事务分支提交,部分事务分支回滚,从而导致数据丢失或者不一致。
社区版MySQL事务故障恢复技术
MySQL事务处理的基础知识简介
为了本文后面章节描述方便,简单罗列一下MySQL的基础知识和概念,已掌握的话可以直接跳过。
MySQL支持多存储引擎,通过其内部定义的Handler接口与存储引擎交互。目前常用的支持事务处理的存储引擎(简称事务存储引擎,transactional storage engine)是InnoDB,InnoDB也是MySQL目前默认的存储引擎。同时MySQL社区还有MyRocks,它包含RocksDB并且为RocksDB存储引擎实现了HANDLER接口,使得MySQL可以使用RocksDB这个事务存储引擎。
MySQL通过binlog事件流把数据更新传输给备机节点,备机重新执行这些binlog事件,从而获得与主节点相同的数据,成为主节点的一个实时可用的备用节点,这就实现了高可用(high availability, HA) 。Binlog系统在MySQL中也被当做一种存储引擎,实现了HANDLER接口。不过,binlog系统本身并不支持事务处理,不能做事务回滚或者恢复。Binlog文件达到一定大小后,MySQL会自动切换到一个新的binlog文件,这些文件依次升序编号。老旧不用的binlog文件会被DBA删除(purge)掉来释放存储空间。
在启用binlog系统和gtid_mode=on的情况下,每个MySQL的事务使用一个gtid来唯一标识,gtid包含了主节点的UUID和单调递增的顺序号,由MySQL自动分配(本文不讨论GTID的其他边缘用法)。系统表mysql.gtid_executed 会详细记录一个MySQL实例执行过的所有gtid的集合。因此,一个MySQL实例的这3个事务集合必须相同,这也是MySQL 数据一致性条件:
1、binlog中记录过的所有事务的集合(尽管其中大多数后来都会被purge掉)
2、存储引擎中执行过的事务的集合
3、mysql.gtid_executed中记录着的gtid所属的事务的集合
这是MySQL binlog recovery的目标。对于普通事务,社区版MySQL实现了这个目标,但是对于XA事务,社区版MySQL完全忽略了,没有做任何处理。kunlun-storage完整地支持了XA事务的故障处理,可以确保XA事务也符合上述一致性要求。
本文所述的技术基于这个常用的也是数据一致性保障级别最高的设置,这也是KunlunBase要求必须使用的设置:启用binary logging, gtid_mode=on,sync_binlog=1, innodb_flush_at_trx_commit=1。
社区版MySQL的事务处理流程
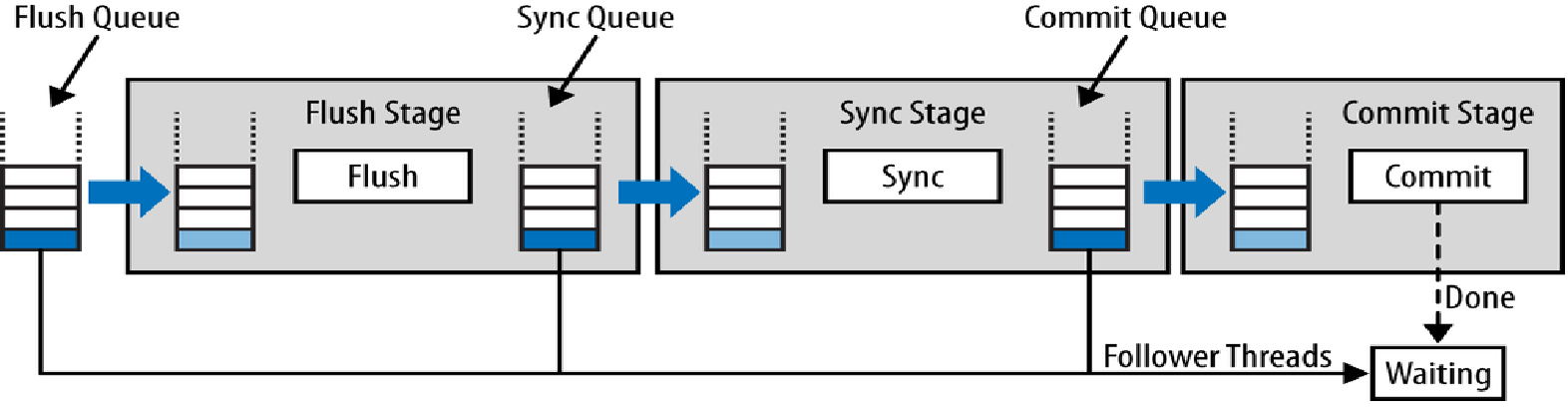
MySQL 3阶段事务提交流水线示意图
社区版MySQL使用binlog做主备复制实现高可用,本文描述在启用了binlog的情况下,MySQL异步复制或者半同步复制的情况下,提交事务的流程。kunlun-storage的fullsync 也遵循这个流程。
MySQL提交一个事务trx需要把trx的binlog写到binlog文件,并且把trx在每个存储引擎的WAL日志写到其事务日志文件中。具体的流程如上图,是一个三阶段流水线。在开始这个三阶段事务提交流水线之前,每个事务先在各自的线程中完成engine prepare(存储引擎prepare),flush自己的innodb/myrocks等事务存储引擎的redo log 到持久存储设备。
敏锐的读者可能已经发现,MySQL提交事务也是做了两阶段提交,先prepare,然后在下文的三阶段提交流水线中写完binlog后再commit。之所以这么做,是因为binlog也相当于是MySQL的一个存储引擎,它以binlog事件的形式存储了每个事务的数据更新,并且MySQL需要保持binlog与innodb等真正的事务存储引擎中的事务集合相同。
这就要求事务存储引擎支持两阶段提交,目前InnoDB和RocksDB是支持两阶段提交的,可以作为MySQL的事务存储引擎。
MySQL事务提交的三阶段流水线
MySQL备机复制逻辑需要让binlog中的每个事务的所有binlog事件按其发生顺序依次写入binlog文件,并且一个事务写完后再写下一个事务的binlog事件。在MySQL-5.7开始支持了基于GTID的复制技术之后,每个事务在binlog中的出现顺序需要与其gtid顺序相同。为了以最大的并发性能实现这些顺序保障,MySQL通过三阶段提交流水线技术实现大量并发事务组提交。
1、Flush阶段
首先并发提交的若干个事务进入flush队列,然后按照其在队列中的顺序获取gtid。这个gtid描述了这些事务提交的先后顺序,并且在一个MySQL主备复制集群(对应于KunlunBase的存储集群)中唯一标识一个binlog中的事务(严格说叫做event group, 其区别很小不影响理解,文末再详述),也是备机做并行复制的依据。然后,队列的leader线程依次flush这个flush队列中的每个事务的binlog 事件(flush之前缓存在其会话中)到当前binlog文件中。这就确保了事务的binlog在binlog文件中的顺序与其gtid的顺序严格对应。
2、Sync 阶段
Flush阶段完成后,flush队列中的事务整体离开flush队列并且进入sync队列。空出的flush队列就可以让下一批事务进入。通常对于一个负载较重的MySQL实例来说,此时已经有一些事务在等待进入flush队列了。它们进入flush队列后开始上述flush阶段。而这些进入sync队列的事务由其leader线程代做一件事 --- sync 这个被写入binlog的binlog文件 --- 把flush阶段写入的binlog文件内容从操作系统的page cache中sync到磁盘中,这样这组事务的binlog就在此服务器上永久存储。
完成sync阶段后,sync队列中的事务进入engine commit阶段。
3、Engine Commit 阶段
如上文所述,在开始三阶段流水线之前,这些提交流程中的事务首先做的就是做engine prepare。 此时这些事务在事务存储引擎中仍然是PREPARED状态,所以engine commit阶段完成这些事务在事务存储引擎(InnoDB或者MyRocks)的提交(commit)阶段。
提交的方法有两种:进入commit队列由leader线程依次commit每个事务,或者每个事务在各自工作线程中独立完成commit,这两种方法的选择由系统变量binlog_order_commits控制。
由leader线程依次commit(binlog_order_commits=true) 的好处是可以实现极致的一致性--- 每个事务提交的顺序 --- 也就是其他事务中可以看到正在提交的这些事务的数据更新的顺序--- 与它们在binlog中出现的顺序完全相同。不过缺点就是性能相对偏低,因为这些事务是由一个线程依次commit的,没有发挥多核CPU和高性能SSD磁盘的并发能力。
每个工作线程独立commit(binlog_order_commits=false)刚好具有相反的效果,可以充分发挥并发能力,性能更好;不过缺点是,事务实际完成提交的顺序与它们在binlog文件中出现的顺序并不严格相同,不过对于绝大多数场景来说这种顺序差异并不是个问题。因此在KunlunBase kunlun-storage的配置文件模板中,我们始终设置binlog_order_commits=false.
MySQL实例故障可能造成的错误
如果没有可靠的事务恢复技术,那么MySQL实例故障可能导致主节点上提交的某个事务T在binlog中不存在,但是在innodb中存在,或者在binlog存在但是innodb中不存在,那么备机数据就会与主节点数据不同(主备节点数据不一致);这种主备数据不一致会导致在主节点可以正确执行的数据更新操作,到了备机复制执行会出错 --- 例如,因为某个需要备更新或者删除的行在备机完全不存在或者某个要插入的行在备机已经是存在的 --- 这会导致主备复制卡住,于是这些备机就无法继续复制主节点更新,MySQL主备复制集群就失去了高可用能力。
在使用gtid模式(gtid_mode=on)的情况下,MySQL在建立主备连接时会对比主备节点执行的gtid集合,此处分别记为 Gtid_set_master和gtid_set_slave, MySQL会要求gtid_set_slave是gtid_set_master的子集,否则拒绝建立主备复制关系。因此上述不匹配情况会导致无法建立主备复制关系,因而导致集群失去高可用能力,主节点故障后系统丢失数据和停止服务。
所以在MySQL服务器启动期间需要对齐binlog与事务存储引擎,达到前述的“MySQL****数据一致性条件”,我们把这个过程叫做binlog recovery。
对于普通事务(begin...commit 事务,或者autocommit的语句事务),社区版MySQL可以正确地完成binlog recovery;对于XA事务,社区版MySQL没有正确地实现XA PREPARE,并且也没有做任何binlog recovery恢复工作,这就会导致如下一系列问题。下文详述这两部分内容,以及KunlunBase团队对于MySQL XA事务处理的完善和增强。
社区版MySQL对普通事务的binlog recovery流程
在存储节点故障时,没有prepare的活跃事务在mysqld启动期间会被事务存储引擎全部回滚,并且它们在binlog文件中完全不存在。所以这些事务不会造成任何问题。如果故障时事务已经完成全部提交流程,那么这个事务一定会被存储引擎正确地恢复出来,无需其他处理。
对于那些正在提交的事务,它们可能处于engine prepare阶段、flush阶段、sync阶段或者commit阶段。如果一个事务完成了sync阶段,或者完成了flush阶段并且服务器OS没有重启,则其binlog在故障恢复期间一定存在,此事务就可以提交;否则就必须回滚,这就是binlog recovery阶段需要做的事务恢复工作。
对于普通事务,社区版MySQL可以正确地完成binlog recovery 恢复工作,方法是:从binlog中最后一个文件(标记为LB)的prev_gtids_log_event中获得LB之前所有binlog文件中出现过的事务的gtid集合S0,然后扫描LB得到此文件中所有事务的gtid集合S1,然后计算这个MySQL实例中执行过的所有事务的gtid集合S = S0 + S1。
然后对于每一个事务存储引擎(InnoDB, MyRocks) TXN_SE,
1、获取TXN_SE恢复出的所有prepared状态的事务的集合txns_prepared
2、对于txns_prepared中的每一个事务txn, 如果txn.gtid 在S中(说明txn的binlog存在于binlog文件中),则提交txn,否则回滚txn。
这就可以确保每一个TXN_SE中所有PREPARED状态的事务txn,如果txn在binlog中不存在,则txn在TXN_SE中都会被回滚;如果txn在binlog中存在,则txn在TXN_SE中都会被提交。这样mysqld启动后所有恢复后的普通事务就达到了“MySQL****数据一致性条件”。
社区版MySQL XA事务处理的缺陷及其kunlun-storage中的修复
对于XA事务来说,社区版MySQL有一系列问题,本节依次详述。考虑到上述严重的潜在危害,我们需要完善和改进MySQL对XA事务处理的错误处理和故障恢复能力,以便kunlun-storage可以正确地恢复出XA事务分支,这样在KunlunBase集群层面KunlunBase才可以正确地恢复故障发生时刻正在提交的那些全局事务。恢复最关键的一环,就是存储节点要正确地恢复其本地XA事务分支。
XA PREAPRE写binlog的时机错误
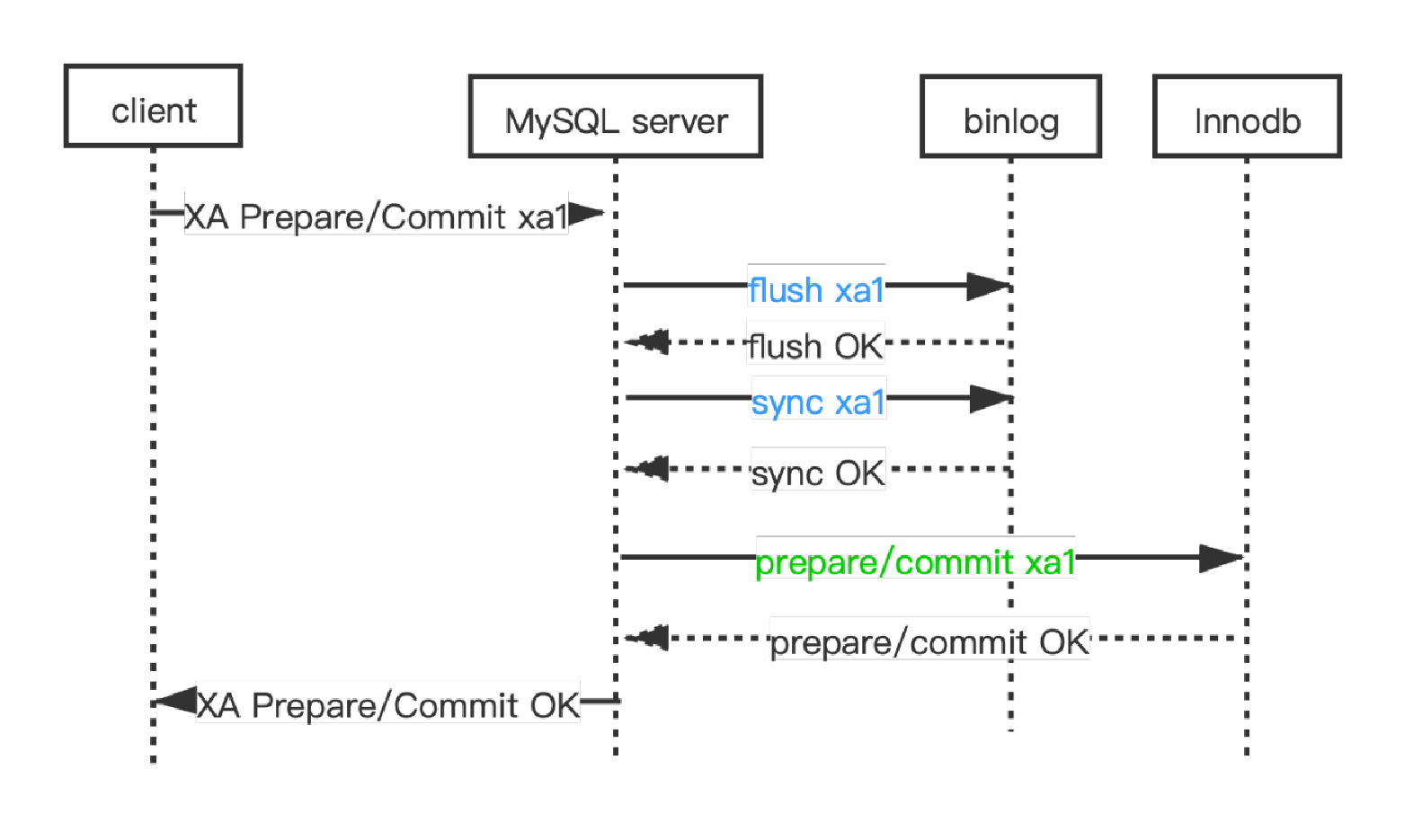
社区版MySQL的XA PREPARE和XA COMMIT的处理流程
社区版MySQL执行XA PREPARE的流程如上图,它先在上述三阶段提交流水线中flush&sync binlog,然后执行engine prepare。
这样做的问题在于,如果在flush&sync binlog之后和engine prepare完成之前,这个XA事务xa_txn1的所有binlog事件已经完整地传输到备机,然后主节点的mysqld 因为各种软硬件故障退出了,那么mysqld重启之后,xa_txn1在InnoDB等事务存储引擎不存在,但是xa_txn1在主机的binlog中是存在的,在此主节点的备机节点中也是存在的。也就是说,主备数据不一致了,“MySQL数据一致性条件”也不成立了,所以这就是严重的错误。
解决方法就是调整XA PREPARE中flush&sync binlog的时机,在所有事务存储引擎完成prepare之后,再flush&sync XA 事务的binlog。不过这样调整顺序后,又会导致一个新的问题 --- clone功能不工作了。
Klustron-storage 中XA PREPARE的执行流程以及支持clone功能
Kunlun-storage并不依赖clone功能,因为clone只有InnoDB支持,其他存储引擎目前都不支持。Kunlun-storage做物理备份仍然使用XtraBackup。不过,我们仍然决定完善InnoDB clone针对XA事务的支持,确保kunlun-storage功能的完整性。
Clone要求在没有传输binlog的情况下,新节点的mysql.gtid_executed表中存储着的gtid集合就等价于这个MySQL实例执行过的所有的事务的gtid集合。也就是:
对任意事务t, t 在InnoDB中 <=> t.gtid 在mysql.gtid_executed表中
这也是“MySQL 数据一致性条件”中的条件之一。
为此,MySQL的做法是在事务提交期间在InnoDB的undo log中也存储这个事务的gtid,然后后台线程gtid_persistor 可以随后flush这个gtid到mysql.gtid_executed表中。Clone得到的新实例拥有源实例的所有有效的undo log,因此其gtid_persistor可以把gtid合并到mysql.gtid_executed表中,从而满足“MySQL 数据一致性条件”。 为此,InnoDB的purge线程只有在一个事务的gtid被flush到mysql.gtid_executed表中之后才会purge这个事务的undo log。
调整了XA PREPARE 内部执行顺序后,也就是现在先执行engine prepare,然后才做binlogflush&sync,那么在执行InnoDB prepare这一步骤的时候,事务的gtid还没有产生,因为gtid是在进入三阶段流水线的flush队列后才能产生的。所以在kunlun-storage中,执行XA事务的innodb prepare时候我们不写入gtid到其undo log中。而是在进入flush队列并且获得了gtid后,对每个事务依次把其gtid写入其innodb undo log。最后在sync阶段完成后再把gtid交给gtid_persistor来合并到mysql.gtid_executed表中(这一步的原因后文详述)。如下图所示。
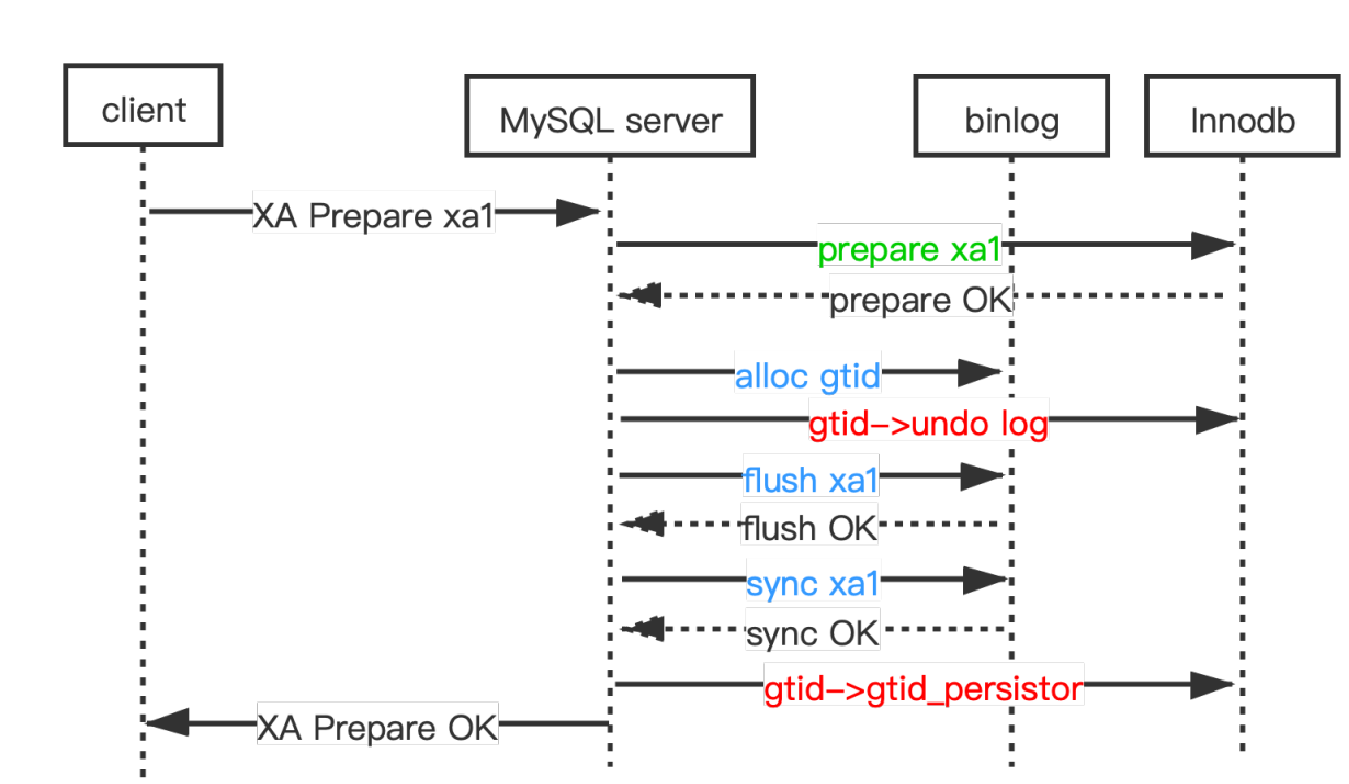
kunlun-storage中XA PREPARE的执行流程示意图
社区版MySQL在binlog中没有记录PREPARED状态的XA事务
MySQL中一个XA事务的两个阶段作为两个不同的binlog event group(BEG)记录在binlog中,每个BEG有唯一的gtid,即使同一个XA事务的两个阶段的BEG的gtid也各不相同。而且这两个BEG有可能分布在两个不同的binlog文件中。这就意味着如果我们要找到所有PREPARED状态的XA事务的binlog,我们就要遍历所有binlog文件中的所有binlog事件,这会带来巨大的IO和计算负载,甚至老旧的binlog文件被purge的情况下,我们可能因为没有找到其binlog,会按照上节描述的算法误回滚本来应该保持PREPARED状态的XA事务。
kunlun-storage解决此问题的方法是在每个binlog文件的头部prev_gtid_log_event中记录当前实例中所有处于PREPARED状态的XA事务id的集合。这样,binlog recovery期间我们只需要打开最后一个binlog文件,用其中的prev_gtid_log_event中记录的XA事务id的集合X0,加上最后这个binlog文件中找到的所有的XA_PREPARE_log_event事件的XA事务ID组成的集合X1,得到集合X_prepared。扫描最后一个binlog文件期间,kunlun-storage还会分别记录所有XA COMMIT和XA ROLLBACK 事件的XA事务id集合到X_committed和X_aborted。这三个集合会在kunlun-storage的binlog recovery流程中使用。
Kunlun-storage对XA事务的故障恢复方法
首先,在InnoDB启动恢复期间,如果发现一个XA事务需要gtid但是其undo log中没有gtid,就回滚这个事务。
在binlog recovery期间恢复每个事务存储引擎返回的prepared状态的事务时,针对XA事务xa_txn1需要做这些恢复工作:
用xa_txn1的XA事务ID(下文记为 xa_txn1.xa_txn_id)查找集合X_prepared,如果找不到(即xa_txn1 的第一阶段binlog在binlog文件中不存在),也就是等价于在上文中描述的S集合中没有找到其xa_txn1.gtid,则xa_txn1没有完成XA PREPARE。不过与普通事务不同的是,XA事务不仅可以两阶段提交,也可以一阶段提交,如何提交由GTM决定,详见前面章节。因此如果xa_txn1是一个一阶段提交的事务,那么binlog recovery过程会检查xa_txn1.xa_txn_id是否在X_comitted中,如果在其中则提交xa_txn1。除了上述情况,其他情况下xa_txn1既没有完成XA prepare也没有完成一阶段提交的binlog flush&sync,仅仅完成了这两个操作的engine prepare操作,所以回滚xa_txn1。
在sync阶段完成之后,xa_txn1的XA PREPARE一定会被执行,因为sync完成后这个BEG一定会在binlog中存在,并且在innodb等事务存储引擎中存在(尽管它可能在第二阶段被回滚),所以sync阶段完成后再把gtid交给gtid_persistor,就可以确保在mysql.gtid_executed表中的每个gtid一定属于在存储引擎中执行过的事务并且在是在binlog中存在过的event group。
如果在X_committed中找到了xa_txn1.xa_txn_id 就提交xa_txn1; 否则如果在X_aborted中找到了xa_txn1.xa_txn_id 就回滚xa_txn1。否则保留xa_txn1为PREPARED状态。这些事务会由KunlunBase的cluster_mgr做后续处理(提交或者回滚)
之所以会出现找到xa_txn1的第二阶段BEG但是xa_txn1却处于PREPARED状态的情况,是因为社区版MySQL和Kunlun-storage执行XA COMMIT和XA ROLLBACK的流程都是先执行binlog flush&sync,然后执行engine commit。这个方法是正确的,不过如果binlog写入之后,engine commit完成之前,MySQL实例故障了,那么重启后,就会发现xa_txn1第二阶段的binlog在binlog文件中,但是xa_txn1仍然是PREPARED状态。社区版MySQL无法恢复XA事务,但是kunlun-storage可以正确地恢复。
总结
经过上述对社区版MySQL事务故障处理的完善和增强,kunlun-storage组成的KunlunBase集群可以正确地处理其集群任何节点的故障,并保证在KunlunBase集群中所有提交成功的事务的ACID属性。对于一个有2*N+1个节点的shard来说,KunlunBase集群可以在N个存储节点同时故障的情况下,保障数据不丢失损坏并且持续提供数据读写服务。kunlun-storage的XA事务故障处理能力是KunlunBase金融级高可靠性技术体系的重要支柱,是KunlunBase的核心技术体系的重要组成部分,也是对社区版MySQL的重大增强和扩充。